
7月14日,由清华大学计算机科学与技术系黄民烈教授主持的清华-清尚智慧场景创新设计研究院2023年度探索性项目《面向文化科技展示和文博领域的数字人大脑生成技术及应用示范研究》开题汇报会顺利召开。

黄民烈教授做开题汇报
北京理工大学光电学院研究员翁冬冬、清华大学计算机科学与技术系副研究员宋亦旭、北京邮电大学人工智能学院副教授李雅、清华-清尚智慧场景研究院副院长吴琼、北京清尚集团副总经理朱怡静、北京清尚集团设计院副院长宋捷、北京清尚集团专务副总经理郑维坤、北京清尚集团直属项目部负责人李伟、北京青尚集团第一分公司副总经理温俊平等专家出席会议。课题组主要成员列席会议。

专家出席开题会
黄民烈介绍了面向文化科技展示和文博览领域的数字人大脑生成技术项目。该项目将结合数字人和人的共生状态,将功能性AI和拟任性AI结合在一起,形成通用人工智能时代的数字人大脑。该项目重点应用于智慧文博、在线展览、文化与科技知识普及等应用场景下,为需求方训练、生成相应的具有丰富语言表达能力和专业知识的智能数字导览人。用户可以与数字人进行对话交流,向他们学习艺术、科学知识,了解艺术与科学史,面化面向文化科技展示和文博览这个领域,探索应用示范。

01
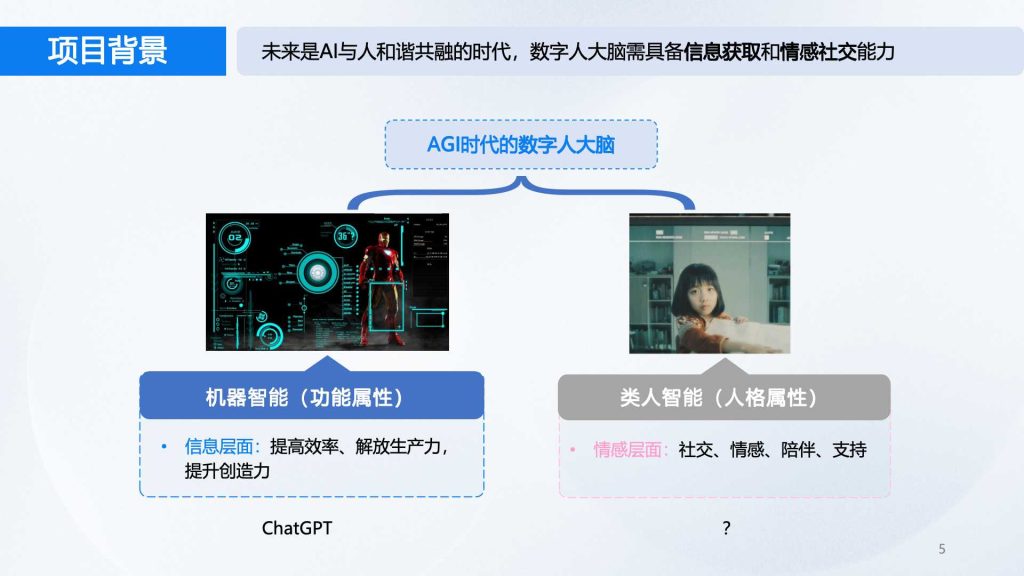
项目背景
大语言模型的能力近年来出现了爆发式增长,大体可分为功能型AI与拟人型AI,未来的通用人工智能将是AI和人和谐共生的状态,不仅能完成任务提高效率,还可以进行情感层面的交流。AGI时代的数字大脑将结合人的人格属性,应用场景包括智慧政务、法务商务、文旅产业、交通和教育等。本项目研究希望在文博领域实现数字人大脑以AI自动驱动实现双向交流,让机器人能真正像人一样对话沟通。

02
项目基础与支撑条件
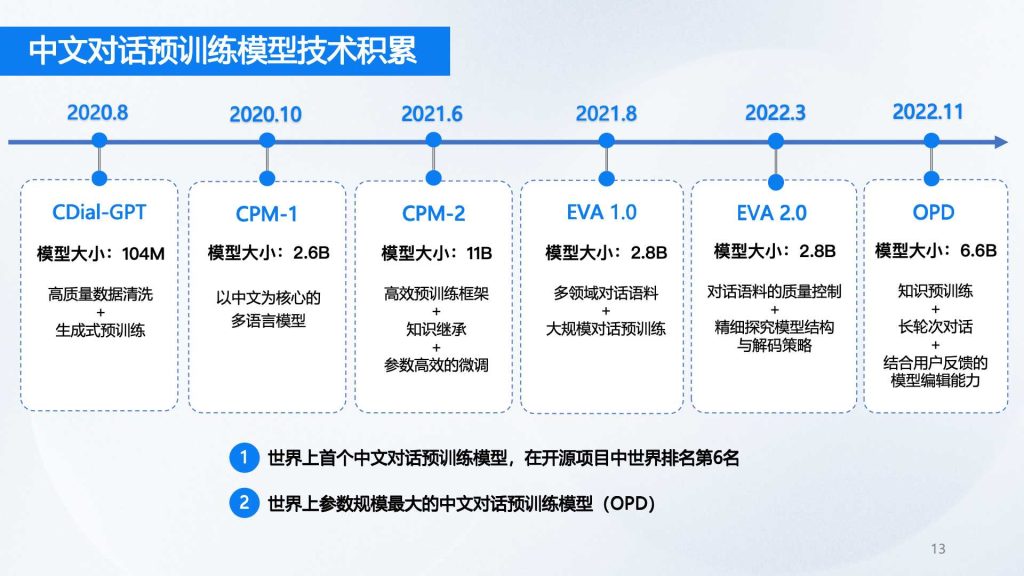
清华大学计算机系教授黄民烈团队在机器人情感对话方向是国内的引领者,在情感智能与拟人化AI方向都取得了丰硕的研究成果。他们在国际顶级会议上发表了超过100篇论文,是国内最佳论文获奖次数最多的团队之一。团队在中文对话预训练模型技术中有积累、具备自主知识产权的拟人对话交互关键技术以及成熟的数字人大脑训练流程。在产品数据、算法和工程团队方面都有比较多的实践经验,能对项目的落地实施提供保障。


03
研究内容与技术路线
研究内容聚焦于三个方面,一是文博领域的基座大模型训练,抓取文化科技领域相关数据,结合知识图谱,建立通识型的大语言模型。二是基于文博大模型的数字人大脑生成,这部分会处理数字人角色对话的数据、外援搜索引擎API、指令微调和人机对齐。第三是数字生命体的创建全流程通路,辅助一些知识的库的配置,做高表现力的语音合成。目前数字人制作流程框架已基本完成,包括概念设计、形象研发设计、模型制作和应用层面,未来将把表情动作的驱动与文字语音信号合成到一起。

04
预期成果和示范应用
预期研究成果包括两部分。第一是智能数字导览人的训练生成和场景应用示范,可用于智慧旅游、在线展览、文化科普等多样化场景。第二是复刻知名艺术家和科学家,实现自由对话交互,推动艺术和科学知识的高效传播。研究成果预计将充分赋能文博领域的展览策划(展前)、观展体验(展中)和观展反馈(展后)全流程阶段。


05
讨论环节
开题汇报得到与会专家组的一致肯定,并与课题组共同探讨了有关数字人大脑的一系列问题。

翁冬冬对如何控制生成式AI的数据安全和伦理道德提出疑虑,提问大模型在面对恶意引导时,如何进行防范?黄民烈表示生成式AI的安全性是一个非常重要的问题。我们具有完整的大模型安全风险评估框架,包括数据、算法、评测等,从多个角度对生成式AI进行控制。恶意引导一直是安全性研究中的一个难题。我们已经设计了很多算法,利用对抗攻击使模型提前暴露风险,进而加以防范。

宋亦旭对于大模型在数字人中扮演什么角色、科学家/艺术家复活计划怎么与大模型发生关联提出问题。黄民烈表示在沉浸式游览和交互场景下,数字人必须要有身份、人物经历、价值观,这是独特的地方,是提供结构化信息之外的功能。这种角色对话的实现需要在基座大模型上继续往前做,需要为对话数据进行详细的标注和充分的训练才能实现,所以是基于大模型的。

李雅提出艺术家复活计划是基于大模型实现的,但大模型很容易一本正经胡说八道,大模型输出错误信息可能会误导用户,如何避免?黄民烈表示这种属于out-of-character的行为,数字人出戏了。这是一个比较难的点,虽然不能根本上解决,但可以尽量缓解,可以用推理和知识进行控制。大模型在机制上是一个随机采样的系统,是不确定的,因此彻底解决的方法仍需探索。对于要求知识精确性、准确性的场景,必须要外接知识库,进行输出控制。

吴琼提出数字人关注的是整体形象。数字人对应真人,真与假之间的过渡,很关键。在文博领域,请特型演员是非常昂贵的,期望数字人能在这方面发挥作用。黄民烈表示大语言模型的语音复刻的能力很强,只要有足够的语料,可以超过90%的复刻,方言输出相对容易。动作驱动稍微较难,这种需要通过素材库和动作绑定来实现,一般是基于规则制定的。翁老师从事的是超写实数字人的研究,数字人大脑加上数字人外壳,就可以形成完整的数字人,可以实现多样的功能,潜力巨大。
朱怡静提问复刻艺术家/科学家的数据量需要多少?如果复刻梵高的角色,那数字人对话的依据是什么?黄民烈表示基座大模型在预训练的时候会见到很多具体人物相关的语料。指令微调中还会采用来自各种人物的对话数据。梵高的角色可认为会分成几个阶段,精神平稳的时候是怎么说话,陷入疯狂的时候是怎么说话,这种说话的风格和形式是大模型在众多不同的人物中学习得到的。
与会专家与课题组成员合影
